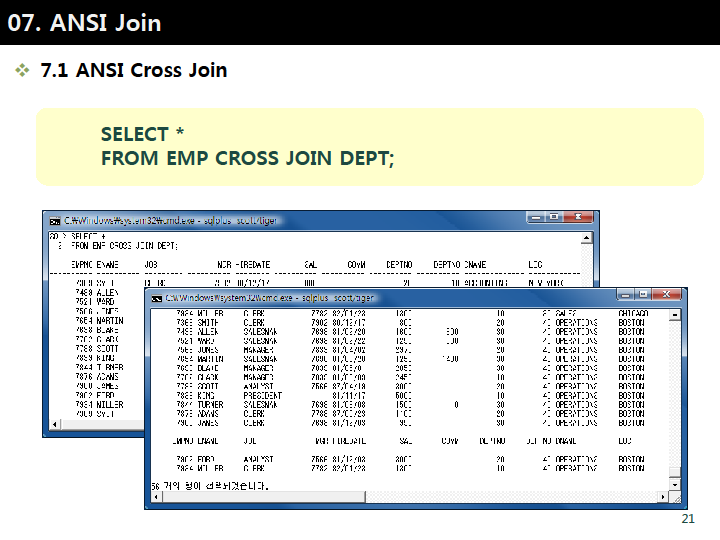
출처 : http://302.pe.kr/379
Oracle SQL Developer
- Oracle SQL Developer is a free integrated development environment that simplifies the development and management of Oracle Database. SQL Developer offers complete end-to-end development of your PL/SQL applications, a worksheet for running queries and scripts, a DBA console for managing the database, a reports interface, a complete data modeling solution, and a migration platform for moving your 3rd party databases to Oracle.
- http://www.oracle.com/technetwork/developer-tools/sql-developer/index.html
♣ 들여쓰기 기본값 변경 하기 (2-->4)
- SQL Developer 의 들여쓰기 기본값은 2.
- 도구>환경설정> 데이터베이스> SQL 포맷터>Oracle 형식 지정>편집>들여쓰기 메뉴에서 값을 변경 할 수 있다.
♣ 들여쓰기에 공백(Space) 대신 탭(Tab) 사용하기
- Preferences -> Database -> SQL Formatter -> Alignment and Indentation -> Use tabulator(도표 작성기 사용) 체크.
♣ Format Code
- 쿼리를 지정 된 포맷에 따라 정렬하기
- 단축키: Ctrl + F7
♣ SQL에디터에서 줄번호 보이게 설정
- 도구 > 환경설정 > 코드 편집기 > 행 여백 > 행 번호 표시에 체크.
♣ 완성 인사이트 대문자로 설정 하기
- 도구 > 환경설정 > 코드 편집기 > 완성 인사이트 > 입력할 때 대소문자 변경 체크 후 'Upper Case'로 설정.
♣ 유용한 단축키 목록
| 범주 | 명령 | 단축키 |
| Worksheet | SQL 워크시트(W) | Alt-F10 |
| Worksheet | 계획 설명(E)... | F10 |
| Worksheet | 내역(H) | F8 |
| Worksheet | 롤백(R) | F12 |
| Worksheet | 명령문 실행 | F9 |
| Worksheet | 명령문 실행 | Ctrl-Enter |
| Worksheet | 비공유 SQL 워크시트 | Ctrl-Shift-N |
| Worksheet | 스크립트 실행 | F5 |
| Worksheet | 자동 추적(A)... | F6 |
| Worksheet | 지우기(C) | Ctrl-D |
| Worksheet | 커밋(O) | F11 |
| 검색 | 다음 찾기(N) | F3 |
| 검색 | 바꾸기...(R) | Ctrl-R |
| 검색 | 이전 찾기(P) | Shift-F3 |
| 검색 | 증분 뒤로 찾기(B) | Ctrl-Shift-E |
| 검색 | 증분 앞으로 찾기(O) | Ctrl-E |
| 검색 | 찾기...(F) | Ctrl-F |
| 검색 | 커서 다음 단어 찾기 | Ctrl-F3 |
| 검색 | 커서 앞 단어 찾기 | Ctrl-Shift-F3 |
| 기타 | SQL 내역: 다음 내역에서 추가 | Ctrl-Shift-Down |
| 기타 | SQL 내역: 다음 내역으로 바꾸기 | Ctrl-Down |
| 기타 | SQL 내역: 이전 내역에서 추가 | Ctrl-Shift-Up |
| 기타 | SQL 내역: 이전 내역으로 바꾸기 | Ctrl-Up |
| 기타 | 고급 형식... | Ctrl-Shift-F7 |
| 기타 | 구현 디버그 | Shift-F9 |
| 기타 | 대문자/소문자/첫 자를 대문자로 | Ctrl-Quote |
| 기타 | 변경 사항 롤백 | F12 |
| 기타 | 변경 사항 커밋 | F11 |
| 기타 | 보기 고정 | Ctrl-Shift-P |
| 기타 | 새로 고침 | Ctrl-R |
| 기타 | 새로 만들기(N)... | Ctrl-N |
| 기타 | 테스트 실행 | F9 |
| 기타 | 파일 실행 | Ctrl-F11 |
| 기타 | 팝업 메뉴 | Shift-F10 |
| 기타 | 팝업 메뉴 | Context Menu |
| 기타 | 팝업 설명 | Shift-F4 |
| 기타 | 편집(E) | Ctrl-L |
| 기타 | 형식 | Ctrl-F7 |
| 데이터 편집기 | 데이터 필터링 | Ctrl-Alt-F |
| 데이터 편집기 | 변경 사항 롤백 | F12 |
| 데이터 편집기 | 변경 사항 커밋 | F11 |
| 데이터 편집기 | 새로 고침 | Ctrl-R |
| 데이터 편집기 | 선택된 행 삭제 | Ctrl-D |
| 데이터 편집기 | 정렬... | Ctrl-Alt-S |
| 데이터 편집기 | 행 삽입 | Ctrl-I |
| 도구 | 공백 표시 | Ctrl-Shift-W |
| 도움말 | 뒤로 | Ctrl-Alt-Left |
| 도움말 | 문맥에 따른 도움말 | F1 |
| 도움말 | 문맥에 따른 도움말 | Shift-F1 |
| 도움말 | 앞으로 | Ctrl-Alt-Right |
| 디버그 | 감시...(W) | Ctrl-F5 |
| 디버그 | 검사...(I) | Ctrl-I |
| 디버그 | 내부 이동 | F7 |
| 디버그 | 외부 이동 | Shift-F7 |
| 디버그 | 이동 계속(C) | Shift-F8 |
| 디버그 | 재개 | F9 |
| 디버그 | 전체 이동 | F8 |
| 디버그 | 종료 | Ctrl-F2 |
| 디버그 | 중단점 토글(T) | F5 |
| 디버그 | 커서까지 실행(U) | F4 |
| 디버그 | 프로젝트 디버그 | Shift-F9 |
| 버전 지정 | 속성(버전 지정) | Ctrl-Shift-O |
| 보기 | 로그(L) | Ctrl-Shift-L |
| 보기 | 중단점(B) | Ctrl-Shift-R |
| 소스 | 모두 축소(A) | Ctrl-Shift-Open Bracket |
| 소스 | 모두 확장(L) | Ctrl-Shift-Close Bracket |
| 소스 | 재형식화 | Ctrl-Alt-L |
| 소스 | 재형식화 | Alt-Shift-F |
| 실행(R) | 프로젝트 실행 | F11 |
| 이동 | 0~9 책갈피 토글 | Ctrl-Shift-0 ~9 |
| 이동 | 0~9 책갈피로 이동 | Ctrl-0 ~9 |
| 이동 | Maximize Toggle | Ctrl-Alt-M |
| 이동 | 기호 문서 찾아보기... | Alt-Shift-Minus |
| 이동 | 기호 찾아보기...(M) | Ctrl-Minus |
| 이동 | 다음 메시지로 이동(X) | Alt-F8 |
| 이동 | 다음 책갈피로 이동(O) | Ctrl-Q |
| 이동 | 뒤로(C) | Alt-Left |
| 이동 | 앞으로(W) | Alt-Right |
| 이동 | 이전 메시지로 이동(V) | Alt-F7 |
| 이동 | 이전 책갈피로 이동(P) | Ctrl-Shift-Q |
| 이동 | 책갈피 토글(T) | Ctrl-K |
| 이동 | 책갈피로 이동...(B) | Ctrl-Shift-K |
| 이동 | 최근 파일로 이동(F)... | Ctrl-Equals |
| 이동 | 최근 편집으로 이동(E) | Ctrl-Shift-Backspace |
| 이동 | 행으로 이동...(G) | Ctrl-G |
| 창 | 다음 창(X) | F6 |
| 창 | 다음 파일(N) | Ctrl-F6 |
| 창 | 다음 파일(N) | Ctrl-Tab |
| 창 | 오른쪽 편집기(G) | Alt-Page Down |
| 창 | 왼쪽 편집기(E) | Alt-Page Up |
| 창 | 이전 창(V) | Shift-F6 |
| 창 | 이전 파일(P) | Ctrl-Shift-F6 |
| 창 | 이전 파일(P) | Ctrl-Shift-Tab |
| 창 | 파일 목록(F) | Alt-0 |
| 창 | 편집기 메뉴 표시(S) | Alt-Minus |
| 코드 편집기 | 다음 단어 시작 부분까지 삭제 | Ctrl-Delete |
| 코드 편집기 | 다음 단어 시작 부분까지 삭제 | Ctrl-T |
| 코드 편집기 | 다음 단어 시작 부분으로 이동 | Ctrl-Right |
| 코드 편집기 | 뒤로 이동 | Left |
| 코드 편집기 | 로컬 탭 크기를 2로 설정 | Ctrl-2 |
| 코드 편집기 | 로컬 탭 크기를 4로 설정 | Ctrl-4 |
| 코드 편집기 | 로컬 탭 크기를 8로 설정 | Ctrl-8 |
| 코드 편집기 | 매개변수 인사이트(P) | Ctrl-Shift-Space |
| 코드 편집기 | 삽입 모드 토글 | Insert |
| 코드 편집기 | 새 행 삽입 | Shift-Enter |
| 코드 편집기 | 새 행 삽입 | Enter |
| 코드 편집기 | 선택 사항 뒤로 이동 | Shift-Left |
| 코드 편집기 | 선택 사항 복제 | Ctrl-Shift-D |
| 코드 편집기 | 선택 사항 아래로 이동 | Shift-Down |
| 코드 편집기 | 선택 사항 앞으로 이동 | Shift-Right |
| 코드 편집기 | 선택 사항 위로 이동 | Shift-Up |
| 코드 편집기 | 선택 사항을 다음 단어 시작 부분으로 이동 | Ctrl-Shift-Right |
| 코드 편집기 | 선택 사항을 이전 단어 시작 부분으로 이동 | Ctrl-Shift-Left |
| 코드 편집기 | 선택 사항을 파일 끝으로 이동 | Ctrl-Shift-End |
| 코드 편집기 | 선택 사항을 파일 시작 부분으로 이동 | Ctrl-Shift-Home |
| 코드 편집기 | 선택 사항을 페이지 아래로 이동 | Shift-Page Down |
| 코드 편집기 | 선택 사항을 페이지 위로 이동 | Shift-Page Up |
| 코드 편집기 | 선택 사항을 행 끝으로 이동 | Shift-End |
| 코드 편집기 | 선택 사항을 행 시작 부분으로 이동 | Shift-Home |
| 코드 편집기 | 선택 해제 | Ctrl-Back Slash |
| 코드 편집기 | 선행 공백을 탭으로 변환 | Ctrl-Shift-T |
| 코드 편집기 | 선행 탭을 공백으로 변환 | Ctrl-Shift-U |
| 코드 편집기 | 스마트 완성 인사이트(A) | Ctrl-Alt-Space |
| 코드 편집기 | 아래로 이동 | Down |
| 코드 편집기 | 앞으로 이동 | Right |
| 코드 편집기 | 역방향 탭 | Shift-Tab |
| 코드 편집기 | 완성 인사이트(C) | Ctrl-Space |
| 코드 편집기 | 위로 이동 | Up |
| 코드 편집기 | 이전 단어 시작 부분까지 삭제 | Ctrl-Backspace |
| 코드 편집기 | 이전 단어 시작 부분으로 이동 | Ctrl-Left |
| 코드 편집기 | 이전 문자 삭제 | Shift-Backspace |
| 코드 편집기 | 이전 문자 삭제 | Backspace |
| 코드 편집기 | 일치하는 중괄호까지 선택 | Alt-Shift-Close Bracket |
| 코드 편집기 | 일치하는 중괄호까지 선택 | Alt-Shift-Open Bracket |
| 코드 편집기 | 일치하는 중괄호로 이동 | Alt-Open Bracket |
| 코드 편집기 | 일치하는 중괄호로 이동 | Alt-Close Bracket |
| 코드 편집기 | 취소 | Escape |
| 코드 편집기 | 탭 삽입 | Tab |
| 코드 편집기 | 파일 끝으로 이동 | Ctrl-End |
| 코드 편집기 | 파일 시작 부분으로 이동 | Ctrl-Home |
| 코드 편집기 | 행 끝까지 삭제 | Ctrl-Shift-Y |
| 코드 편집기 | 행 아래로 스크롤 | Ctrl-Down |
| 코드 편집기 | 행 위로 스크롤 | Ctrl-Up |
| 코드 편집기 | 행 조인 | Ctrl-J |
| 코드 편집기 | 행 주석 토글(T) | Ctrl-Slash |
| 코드 편집기 | 행 주석 토글(T) | Ctrl-Shift-Slash |
'DB > M' 카테고리의 다른 글
| [SQLite] 파이썬에서 (0) | 2021.02.09 |
|---|---|
| [ORACLE SQL] 계정생성 in cmd (0) | 2020.11.16 |
| [ORACLE SQL] 시퀀스 1로 초기화 (0) | 2020.11.16 |
| [ORACLE SQL] 기본 & 함수 문제 풀기 (0) | 2020.11.10 |
| [ORACLE SQL] 업체코드6552 에러 (0) | 2020.11.10 |